Mastering Evaluations in LangSmith: Enhancing LLM Performance

Introduction
Large Language Models (LLMs) are AI models capable of generating text that resembles human language. They are trained on extensive text datasets and are suitable for various natural language processing tasks, including translation, question answering, and text generation.
Evaluating LLMs is necessary in order to verify their performance and the quality of the text they produce, which is particularly vital when their generated content is used for decision making or offering user information, which means that there is no room for error. But evaluating LLMs is not a one time action, it is a repetitive process that is done over time. Continuous assessment allows us to monitor their progress, identify areas of enhancement, and ensure the generated text remains accurate and of high quality.
This is where LangSmith comes in and plays a key role in simplifying and improving the evaluation of Large Language Models (LLMs) through its platform. It provides tools and features that streamline the assessment process, helping users efficiently analyze and compare model performance to ensure continuous improvement and reliability in their applications.
Understanding LangSmith Evaluations
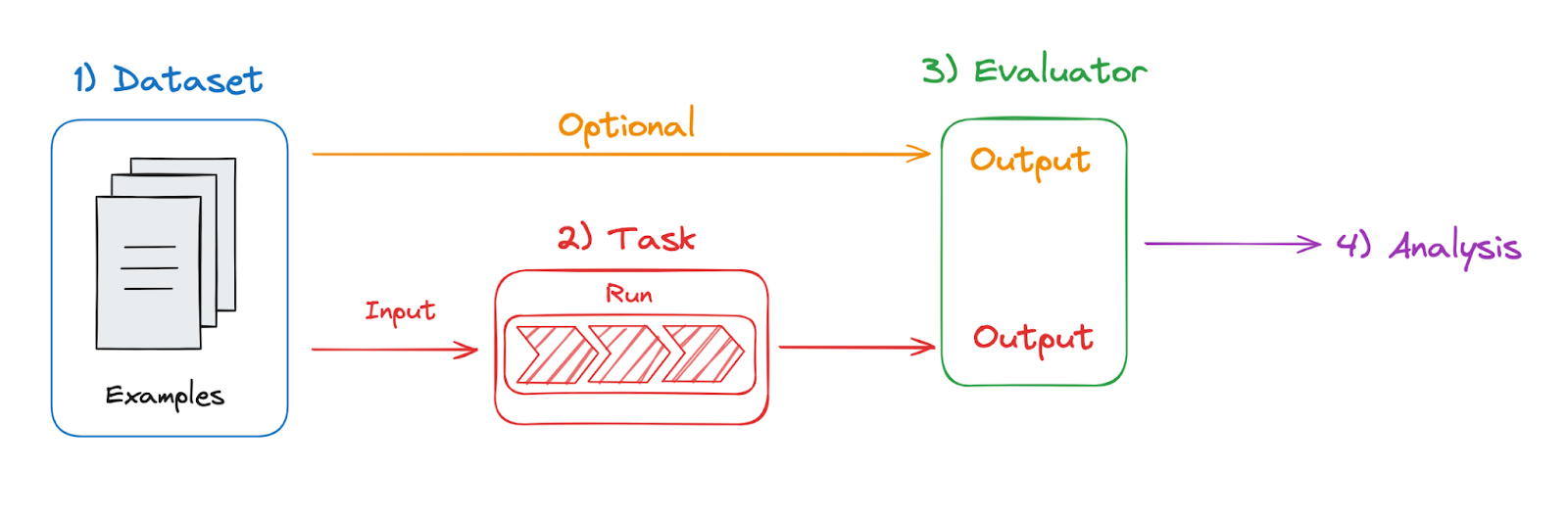
Image by author
According to LangSmith, evaluation refers to a process of assessing the performance of Large Language Models (LLMs) by examining the inputs and outputs of a model, agent, or chain. The goal is to assign a score that reflects the model's effectiveness. This can be achieved through various methods, including comparing the model's outputs against reference outputs or by using other evaluators that don't require reference outputs, such as checking if the generated outputs meet specific criteria. LangSmith provides tools that allow users to run these evaluations on their applications using Datasets, which consist of different Examples.
The main components of an evaluation in LangSmith consist of Datasets, your Task, and Evaluator. Starting with datasets, these are the inputs of your Task, which can be a model, chain, or agent. These datasets can optionally include reference outputs for your evaluator to compare against the Task's outputs, and they can come from various sources, such as manual curation, user input/feedback, or even LLM generation. Then we have the Evaluator, which is any function that generates a score based on the inputs, Task outputs, and, if available, the reference outputs. Additionally, LangSmith offers pre-built evaluators to help you get started quickly.
There are two types of evaluations, reference-based and reference-free. Using these two approaches together will surely provide you with a comprehensive assessment of your Large Language Model (LLM) performance. First, we have reference-based evaluation which involves comparing model outputs against pre-defined reference answers, ensuring the model's output aligns closely with expected results. This approach provides a concrete measure of how accurately a model replicates known answers, enables consistent benchmarking across different models and versions, and helps in fine-tuning models to improve exact match rates for specific queries.
Next, we have reference-free evaluations, and it is essential when evaluating the model's adherence to certain qualitative standards, like format consistency, or when a predefined reference isn't available. This method is valuable for applications that need creative or diverse outputs, like generating text that follows specific syntactic rules.
The Evaluation Pipeline Explained
Now, you might be thinking, what exactly are Datasets? Well, let me break it down for you. Datasets are composed of examples, which form the fundamental unit of LangSmith's evaluation workflow. Examples offer the inputs for running your pipeline and, when relevant, the expected outputs for comparison. Each example in a dataset should adhere to a uniform schema. Examples include "inputs" and "output" dictionaries, and optionally, a metadata dictionary.
In LangSmith, there are three types of datasets and these are kv, llm, and chat. kv (Key-Value) is the default type, accommodating flexible key-value pairs for inputs and outputs, and is suitable for chains and agents needing multiple inputs or outputs. Evaluations might require custom preparation to handle the various keys. Next, there is llm (Large Language Model) which is designed for "completion" style LLMs, where string prompts ("input") map to string responses ("output"). Finally, we have chat which is tailored for LLMs handling structured chat messages, with inputs and outputs stored as lists of serialized chat messages.
Image by author
LangSmith’s workflow starts with choosing a dataset type based on your application (kv, llm, or chat). Then you add examples to the dataset by defining inputs and expected outputs that follow a consistent schema. After that, select one of LangSmith’s off-the-shelf evaluators or create a custom one that suits your use case and then specify the metrics that will be used to score model performance based on the examples.
After setting up your dataset and configuring your evaluator, feed the dataset examples into your chain, model, or agent to generate outputs and then run evaluations. Use the evaluator to compare generated outputs against reference outputs, or assess them based on other criteria.
Finally, analyze results by reviewing scores to understand the model's strengths and weaknesses.
Deep Dive into LangSmith's Evaluation Tools
Evaluator Types
In this section we will go deeper into LangSmith’s evaluation tools and we will be discussing some of the most commonly used types of evaluators available on LangSmith. First, we have Heuristic evaluators, these are essentially functions that are programmed to perform specific checks on the outputs from a system to determine their quality or correctness.
These evaluators are designed to calculate scores based on specific criteria that don't involve comparing outputs to a predefined reference. For example, a heuristic evaluator might check if the output of a system is an empty string, which could indicate a failure in response generation. Another heuristic evaluator could check if the output is valid JSON, which is important for applications where outputs need to be structured data.
Next, we have LLM-as-Judge evaluators, and from its name you probably can deduce that this type of evaluator uses another Large Language Model (LLM) to assess the outputs of a system. An LLM-as-judge can perform more nuanced evaluations like determining if the content is appropriate or checking if the semantic content of the system output matches the intended meaning of a reference output. This can be done without a direct example output for comparison in some cases, making it flexible.
Finally, we have Human evaluators, which involves individuals manually assessing the outputs from a system. This evaluation can be conducted through tools provided by LangSmith, such as an SDK or a user interface. It is best for scenarios where human judgment is crucial, such as evaluating the naturalness of dialogue in a conversational AI, or when fine-grained subjective assessments are needed that automated systems might not accurately capture.
Image by author
Custom vs. Off-the-Shelf Evaluators
As we’ve mentioned before, LangSmith provides both Off-the-Shelf evaluators and the capability for developers to create their own custom evaluators. This flexibility allows developers to choose the most suitable method for assessing the quality and relevance of generated text based on their specific use cases and requirements. LangSmith’s pre-built evaluators can be easily integrated into any project and using these evaluators ensures that the evaluation is standardized. This is particularly useful when comparing results across different runs or experiments, as it maintains consistency in how the outputs are assessed. Since these evaluators are already optimized for performance, developers can save time and resources that would otherwise be spent on developing and testing custom evaluation functions.
However, a critical advantage of creating custom evaluators that pre-built evaluators are missing is that by creating custom functions, developers have complete control over the evaluation criteria, which allows for fine-tuning the evaluators to better align with project goals and standards.
Image by author
So, how do you implement your own custom evaluators? It's simple really. First, Start by clearly defining what specific aspects of the generated text you need to evaluate. This could include criteria like sentiment accuracy, style alignment, or domain-specific accuracy.
Next, Implement the function using your chosen programming language. This function should take the generated text as input and return an evaluation score based on the defined criteria. Before fully integrating the custom evaluator, it’s crucial to test it thoroughly. Use a variety of texts to ensure that the evaluator accurately reflects the desired metrics. Iterate on the function based on the results and feedback.
Finally, Once the custom evaluator is refined and tested, integrate it into your project environment.
Practical Examples
Let’s now discuss some hypothetical scenarios where each evaluator type can be used. So, let’s say a company uses an automated chatbot to handle customer support inquiries. A heuristic evaluator can check if the chatbot's responses are not empty and are syntactically correct.
Another heuristic might verify that the output includes key phrases expected in a customer service interaction, like "How may I help you?" or "Is there anything else I can assist with?", ensuring that the chatbot consistently provides responses that are coherent and contextually appropriate, avoiding cases where it fails to respond or provides irrelevant information.
Another scenario would be that a social media company employs an LLM to review posts and comments to identify and flag potentially offensive content. In this scenario, an LLM-as-judge evaluator can be used to assess the outputs of the moderation LLM, checking if flagged content indeed contains inappropriate material. This evaluator could also compare the semantic meaning of flagged texts against a database of previously identified offensive content to verify accuracy.
Our last scenario would be a news outlet that experiments with using AI to generate short news summaries from longer articles. Here, human evaluators would be best because assessing qualitative aspects of the summaries, such as whether they maintain the nuance and tone of the original articles, is difficult for automated systems to judge.
Evaluating without References
It’s important to mention that reference-free evaluation represents an innovative approach in the field of artificial intelligence and machine learning, particularly with applications involving Large Language Models (LLMs). Let’s mention a few reasons for that, starting with the fact that they are not constrained by the availability of predefined correct answers or outputs, making them flexible and especially useful in scenarios where outputs are dynamic or too diverse to standardize.
Furthermore, reference-free evaluators can also assess the quality of content based on certain standards or guidelines, without comparing them to a specific correct output as well as allowing for broader assessments of system behavior, focusing on general qualities like coherence, engagement, or user satisfaction, which are hard to quantify against a specific reference but are critical for the user experience.
Advanced Evaluation Strategies
Source
Let’s now discuss some advanced evaluation strategies that go beyond basic correctness to assess deeper aspects of generated text such as semantic accuracy and cultural appropriateness. You can use LLMs to judge semantic accuracy which involves evaluating whether the model's output maintains the intended meaning or context of the input or reference text and that is achieved by comparing the semantics of the generated output with a standard or expected response. Techniques that can be used include embedding comparisons, where vectors representing the semantic features of texts are compared, or using secondary LLMs trained to assess semantic accuracy.
Cultural appropriateness in LLM outputs is evaluated by assessing whether the content is sensitive and appropriate to the cultural context of the audience it serves. This involves checking for biases, stereotypes, or potentially offensive content that may not be universally recognized but are inappropriate in specific cultural settings. Here, a combination of human evaluators and LLM-as-Judge can be used. LLMs are used to detect cultural insensitivities or biases in text, while human evaluators are essential for providing insights that current AI might miss, especially in nuanced or emerging socio-cultural contexts.
Integration and Automation
Now has come the time to discuss how to integrate evaluations into the LangSmith platform. First, create datasets by compiling examples that consist of inputs and, if applicable, expected outputs. The schema and structure of these datasets need to be defined to match the requirements of the tasks and evaluators. Next, choose from the Off-the-shelf evaluators or create evaluators based on the type of assessment needed for your models. This includes deciding whether the evaluation will be reference-based or reference-free. Then configure the evaluators to understand and interpret the structure of the datasets they will work with.
Then in the LangSmith platform, the automation of evaluations as part of continuous integration (CI) and continuous deployment (CD) pipelines, along with scheduled and trigger-based evaluations, are all made easy once set up by the user. So, your next step should be to configure and integrate the evaluations into the CI/CD pipelines. Once configured, the execution of these evaluations is automated. Every time a model is updated, the platform automatically triggers the predefined evaluations to ensure the new model version meets the desired performance standards.
You can then schedule evaluations at regular intervals or set up triggers for evaluations based on specific events, such as the addition of new data or changes in data patterns. The running of these evaluations according to the schedule or upon triggering events is managed automatically by LangSmith.
Finally, you can define the performance metrics and thresholds that determine whether a model needs further tuning or retraining. The feedback from these evaluations is automatically processed. If performance metrics fall below the thresholds, the system can flag models for review or automatically initiate retraining processes, depending on the setup.
Conclusion
So, I hope you now understand the importance of systematic and robust evaluations for developing effective Large Language Model (LLM) applications. They ensure that models perform well and evolve in line with dynamic data and user expectations. LangSmith's evaluation tools offer a comprehensive platform for integrating these assessments smoothly into your workflows, providing both off-the-shelf and customizable evaluators to suit various needs. By leveraging LangSmith’s robust evaluation capabilities, developers can not only maintain but continuously enhance the accuracy and reliability of their LLM projects, ultimately leading to more intelligent and responsive applications.


