Optimizing RAG Performance: Enhancing AI with User Feedback and Multimodal Data

Introduction
Retrieval-Augmented Generation (RAG) models represent a transformative approach in artificial intelligence, combining the strengths of generative models such as large language models (LLMs) with targeted information retrieval.
This methodology involves two primary components:
1. Retrieval System that accesses vast knowledge bases to retrieve contextually relevant information.
2. Generative Language Model that utilizes this retrieved data alongside the input query to produce coherent and contextually appropriate responses.
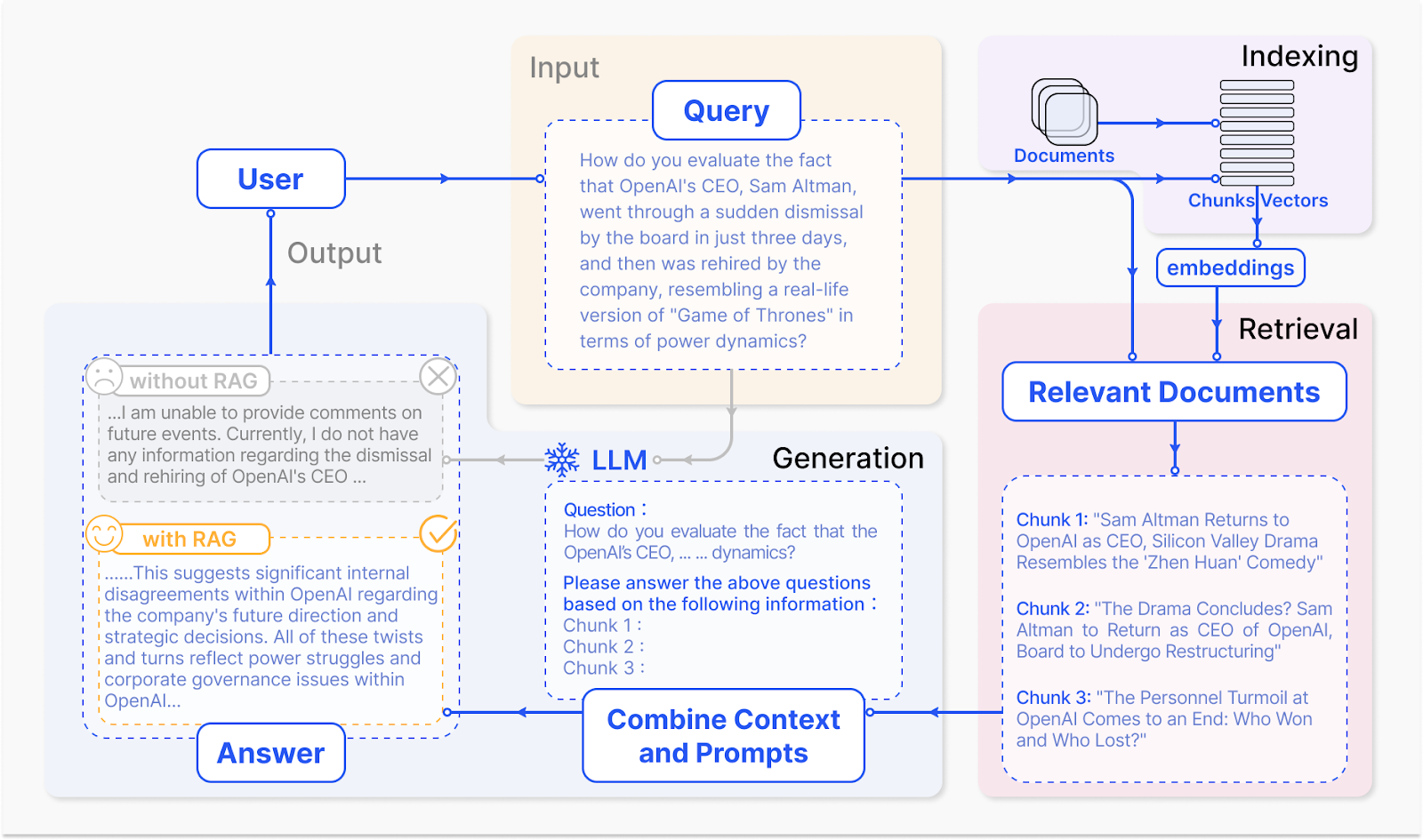
Fig: How a RAG System Operates - Source
Retrieval-Augmented Generation (RAG) presents a solution to some of the limitations faced by LLMs. By using external, context-specific high-quality data and feeding it to the LLM, RAG significantly reduces the likelihood of hallucinations(generating false or irrelevant information). Additionally, RAG can pull data in real-time, overcoming the outdated training data issue inherent in LLMs and reducing the need for continuous LLM retraining, thus saving computational resources.
Organizations want generative AI tools that use RAG because it makes those tools aware of proprietary data without the effort and expense of custom model training. RAG also keeps models up to date by leveraging newer information from private databases for more informed responses rather than relaying solely on the training data. This capability is particularly valuable in several key areas:
- Conversational Agents: RAG improves the relevance and accuracy of responses in real-time by accessing the latest information from knowledge bases.
- Customer Support Systems: By retrieving and integrating recent customer interactions and company policies, RAG ensures that support agents provide the most accurate and helpful responses.
Despite their advanced capabilities, RAG models face several challenges that can hinder their performance. Key issues include the accuracy of retrieval, relevance, and coherence of generated responses, scalability to large datasets, and the integration of diverse data types. Additionally, these models can sometimes struggle with maintaining context over extended interactions and ensuring the reliability of the information they generate. Continuous improvement is essential to address these limitations and meet the growing demands of modern AI applications.
User-Centric Fine-tuning
Incorporating feedback loops from end-users is crucial for refining and improving the outputs of RAG models. User-centric design focuses on the needs and preferences of the end-users, ensuring that the AI system evolves based on real-world usage patterns.
User feedback can be collected through various methods, such as direct feedback forms, interaction logs, ratings, and comments. For a RAG model, important feedback might include the relevance of the information retrieved, the quality of the generated responses, and the overall user satisfaction with the interaction. Once collected, the feedback must be systematically integrated into the training process. This integration can be achieved through:
1. Reinforcement Learning (RL): User feedback serves as a reward signal. The RAG model, acting as an agent, receives positive rewards for responses that meet user approval and negative rewards for less helpful ones.
2. Active Learning: It involves querying users to label the most uncertain outputs generated by the RAG model. By focusing on these uncertain areas, the model can learn from the most informative examples, improving efficiently with less data.
3. Human-in-the-Loop (HITL) Training: Incorporating human feedback directly into the model's training loop allows continuous refinement. For example, a human reviewer could assess the quality of answers generated by the RAG model and provide corrective feedback, which is then used to fine-tune the model.
Adjusting the Retrieval Component
The feedback specifically about the retrieval phase can be used to adjust how the RAG model searches for and prioritizes information from its knowledge base:
- Query Reformulation: If feedback indicates that certain types of queries yield irrelevant information, the model’s query formulation strategy can be adjusted.
- Document Ranking Adjustments: Feedback on document relevance can lead to changes in the algorithms used to rank retrieved documents, potentially incorporating more sophisticated metrics or user-specific preferences.
Fine-Tuning the Generator
Feedback on the generative aspect of the model can be leveraged to improve how it constructs responses:
- Targeted Training: Using identified errors or mismatches in response generation to conduct targeted training sessions. For example, if feedback frequently points out certain factual inaccuracies, those specific areas can be emphasized in the next training cycle.
- Adaptive Generation: Adjusting the generation strategy based on user feedback, such as preferring certain styles or formats (e.g., more concise answers, inclusion of bullet points).
Integrating user feedback has significantly enhanced RAG model performance in various industries such as:
- E-commerce: By analyzing customer queries and purchase behavior, RAG models can offer more personalized product recommendations. Several e-commerce giants like Amazon, Alibaba, and Shopify leverage customer reviews, previous purchase history, and browsing behavior to deliver highly personalized product suggestions.
- Customer Support: Continuous feedback integration allows RAG models to learn from customer interactions, improving response accuracy and the resolution of customer inquiries in real-time. Guesty, a hospitality management software provider, improved the usage of their customer support chatbot from 5.46% to 15.78% by synthesizing data from multiple sources, including previous guest conversations and property details, to offer personalized and context-rich interactions into their RAG system.(Source)
Industry-Specific Implementations
Healthcare

Source: freepik.com
To ensure reliability and accuracy in healthcare using Retrieval Augmented Generation (RAG) models, several strategies are employed:
- Integration with Medical Sources: RAG models in healthcare are integrated with trusted medical databases and literature to retrieve the most current and validated information.
- Human-in-the-Loop (HITL) Verification: Medical professionals review and provide feedback on the outputs generated by the RAG model. This feedback is used to continuously train and refine the model, ensuring that the diagnostic suggestions and treatment recommendations are accurate and clinically relevant.
- Advanced Natural Language Processing (NLP): Enhance the comprehension of complex medical queries by utilizing models trained on medical text datasets to accurately retrieve and synthesize clinically relevant information.
- Regular Audits and Updates: Regularly auditing the model's performance and updating its knowledge base with the latest medical research and clinical guidelines help maintain its accuracy and reliability over time.
Finance

Source: freepik.com
Enhancing RAG models for the finance sector is pivotal for specific tasks such as advancing financial forecasting, fraud detection, and risk management capabilities. For financial forecasting, integrating diverse datasets like historical financial data, market trends, and real-time updates enables accurate scenario analysis, crucial for predicting market outcomes and risks.
Improving fraud detection involves enhancing RAG's ability to detect anomalies in transactional data and analyze customer behaviors using AI algorithms, ensuring swift and precise identification of fraudulent activities.
In risk management, RAG models assess market volatility and regulatory changes to predict and mitigate financial risks, supported by fast data retrieval and analysis for timely decision-making. Precision and speed are paramount in these applications, ensuring reliable insights and proactive strategies in dynamic financial environments.
Hybrid Retrieval Techniques
In a typical RAG pipeline, the initial step involves retrieving relevant documents or passages from a knowledge base to provide context for the LLM. This is where hybrid search plays a crucial role. It blends traditional keyword-based search with semantic search techniques, identifying the most relevant documents from the knowledge base. The combination of keyword-based and semantic search techniques can be more computationally efficient than relying solely on complex neural network-based retrieval models and providing more accurate and informative responses. It enables RAG models to handle a variety of query types from specific factual questions to open-ended exploratory searches. Hybrid Retrieval follows below steps:
1. Keyword-based Search: The hybrid search approach starts with a keyword-based search, leveraging techniques like the BM25 algorithm. This allows the system to quickly identify documents that contain the exact terms or entities mentioned in the user's query. This step ensures precision and helps narrow down the set of relevant documents.
2. Semantic Search: After the initial keyword-based filtering, the hybrid search approach then applies semantic search techniques. This involves using dense vector representations (embeddings) of the query and documents to find semantically similar content, even if the exact keywords don't match. This step helps broaden the search and surface documents that may be relevant based on meaning and context, rather than just literal term matching.
3. Ranking and Scoring: The final step in the hybrid search process is to combine the results from the keyword-based and semantic search components. This is typically done using a weighted scoring function that balances the relevance scores from both approaches, allowing the system to surface the most relevant documents for the given query.
Fig: Hybrid search RAG pipeline: Source
Example: Google uses a hybrid retrieval approach combining keyword-based indexing and semantic search capabilities. This allows Google to deliver highly relevant search results quickly, improving user experience by accurately interpreting the intent behind search queries, even if the exact keywords aren’t used.
Enhancing RAG with Multi-Modal Data
Another approach to optimize RAG applications is to integrate multimodal data, such as semi-structured documents and images, alongside traditional text. Here, we will be exploring three approaches to incorporate multi-modality into your RAG Pipeline using LangChain:
1. Multimodal Embeddings and Retrieval:
- Use multimodal embeddings (such as CLIP) to embed images and text
- Retrieve both using a similarity search
- Pass raw images and text chunks to a multimodal LLM for answer synthesis
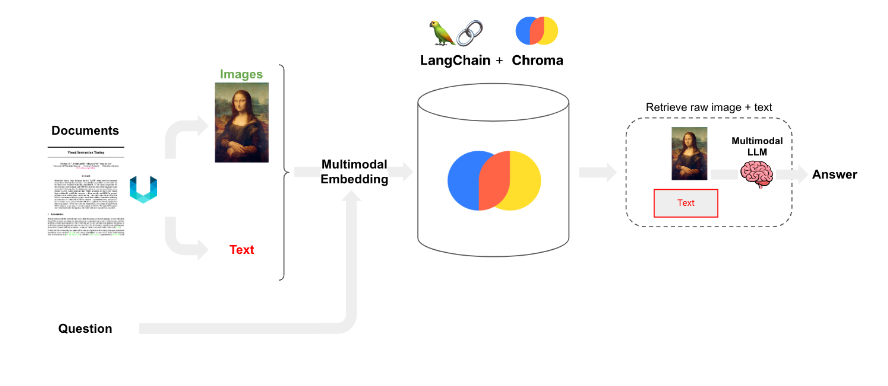
Fig: Langchain Implementation for option 1 : Source
2. Image-to-Text Summarization
- Employ a multimodal LLM (e.g., GPT-4V, LLaVA, or FUYU-8b) to generate text summaries from images.
- Embed and retrieve the text summaries.
- Pass the text chunks to an LLM for answer synthesis.
It is appropriate for cases when a multi-modal LLM cannot be used for answer synthesis due to cost constraints.
3. Multimodal Retrieval and Synthesis
- Use a multimodal LLM to produce text summaries from images.
- Embed and retrieve image summaries with a reference to the raw image using a multi-vector retriever and a Vector DB like Chroma.
- Pass the raw images and text chunks to a multimodal LLM for answer synthesis.
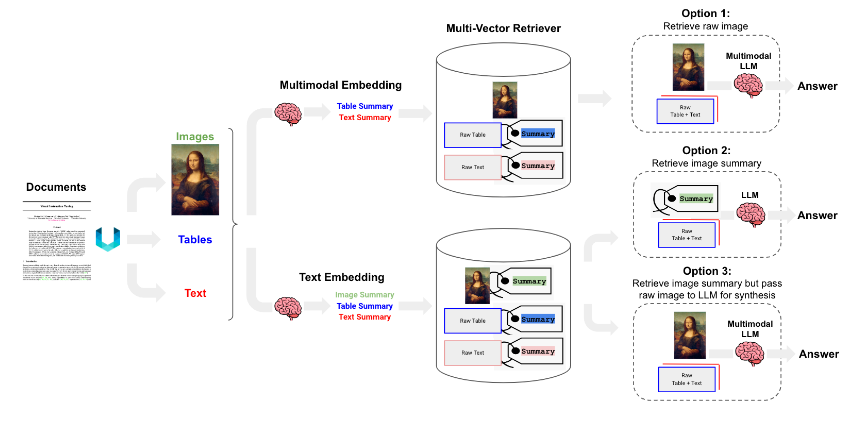
Fig: Langchain Implementation for all options : Source
Example: A Multi-modal RAG model that integrates medical images (X-rays, MRIs) and patient records (text) to assist in diagnostics, provides a comprehensive view of the patient’s condition, leading to more reliable and timely medical advice than the RAG that uses patient records only.
Ethical AI Deployment
In deploying Retrieval-Augmented Generation (RAG) models, ethical considerations are crucial to ensure fairness, transparency, and user privacy. Here are some important considerations to ensure ethical AI Deployment in the RAG pipeline:
- Bias Mitigation: Address biases in the retrieval component of RAG models. Ensure that the retrieved documents or passages are diverse and representative of different perspectives.
- Transparency: Be transparent about the sources used for retrieval. Users should know where the information comes from and how it impacts the generated content.
- Privacy: Protect user privacy during retrieval. Avoid exposing sensitive or personal information from retrieved documents.
- Fairness: Evaluate the fairness of retrieval results. Consider whether certain groups are overrepresented or underrepresented in the retrieved content.
- Feedback Loop: Implement a feedback mechanism where users can report problematic retrieval results. Use this feedback to improve the retrieval process.
A media company used a RAG model for generating news summaries. It was found to frequently cite sources with biased perspectives, affecting the neutrality of the information presented. The company addressed this by diversifying the range of sources in the RAG's retrieval database and implementing algorithms to assess and balance the political orientation of the cited content.
Conclusion
Retrieval Augmented Generation (RAG) models have demonstrated significant advancements in AI, merging deep learning with precise information retrieval to enhance performance across various industries.
As we look forward, emerging technologies like advanced neural embeddings and multimodal data integration promise to push the boundaries of what RAG models can achieve. Continued innovation is essential to meet the evolving demands and challenges in AI, ensuring that RAG models not only become more sophisticated and user-friendly but also adhere to ethical standards.
The journey towards more intelligent, responsive, and responsible AI systems continues, driven by both technological advancements and a deepening understanding of the ethical implications of AI.


