Introduction to LLM Evaluation: Navigating the Future of AI Technologies

Introduction to LLM Evaluation: Navigating the Future of AI Technologies
This article delves into the significance of continuous evaluation of Large Language Models (LLMs) and how innovative frameworks and techniques streamline this process, ensuring the accuracy, reliability, and efficiency of content created by generative ai across diverse applications.
Introduction to LLM Evaluation: Navigating the Future of AI Technologies
As the realm of artificial intelligence continues to expand, large language models (LLMs) have become pivotal in driving technological advancements across a multitude of sectors, including healthcare, finance, and education. These complex models, capable of understanding and generating human-like coherent text, are at the forefront of innovation, offering real-world solutions that range from automated customer support to sophisticated data analysis and beyond.
However, the rapid evolution of LLMs like gpt 4, Llama and Falcon necessitates rigorous evaluation to ensure their reliability and effectiveness. This blog aims to demystify the process of LLM evaluation, emphasizing its critical role as new models continuously push the boundaries of what AI can achieve. We will explore key metrics and frameworks that are essential for assessing LLM performance, providing insights on how to enhance models post-evaluation. Instead of navigating the vast landscape of LLM technologies alone using human evaluation, this guide will equip you with the knowledge to efficiently evaluate and refine these powerful generative ai tools, ensuring they meet the specific demands of diverse applications.
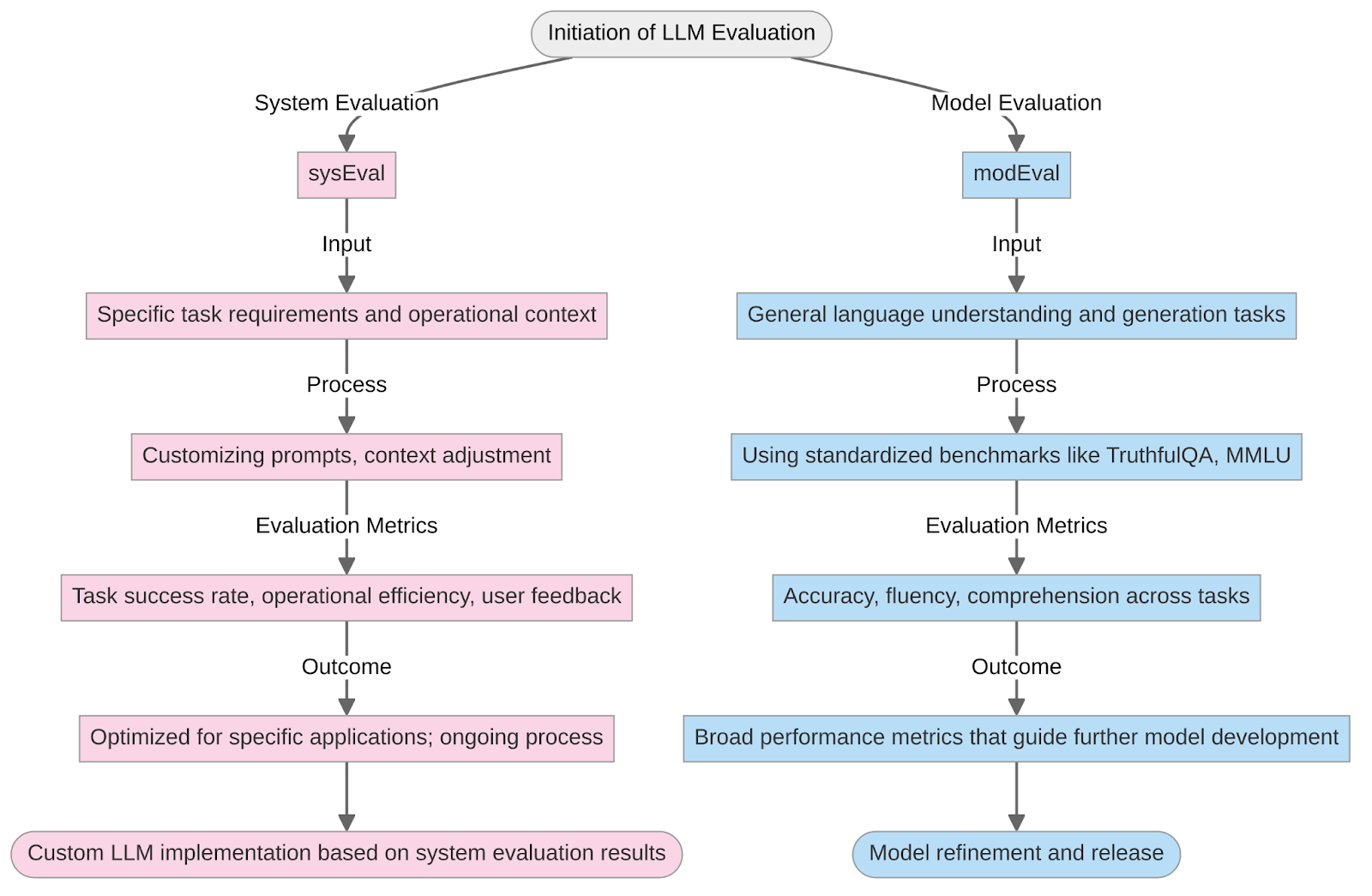
LLM System Evaluation vs LLM Model Evaluation
LLM Model Evaluation:
LLM model evaluations focus on the broad capabilities of these models across a spectrum of tasks. These evaluations are primarily conducted by developers or the organizations that develop these models, aiming to benchmark them against existing models using various metrics. Two notable metrics used in these evaluations are TruthfulQA and Massively Multitask Language Understanding (MMLU), which help in understanding how well these models mimic human behavior and perform general tasks that require language understanding and generation.
- TruthfulQA: This metric measures the accuracy of a model's responses to questions that require factual knowledge, focusing on the truthfulness of the responses. The TruthfulQA benchmark consists of questions designed to reveal whether models can avoid generating false answers that mimic common human misconceptions. This metric is crucial in evaluating how well models can generate factually accurate outputs, particularly in scenarios where providing truthful information is essential. Studies have shown that larger models are generally less truthful, highlighting the challenge of improving truthfulness through scaling alone.
- Massively Multitask Language Understanding (MMLU): MMLU evaluates a model's performance across a wide array of tasks and domains, ranging from elementary-level math to professional law exams. This metric tests the model's ability to understand and generate coherent text in various contexts. By assessing performance across diverse and complex language tasks, MMLU helps gauge the versatility and robustness of a model. The metric is crucial for understanding how well an LLM can handle a broad range of language-related tasks, reflecting its general language comprehension and generation capabilities.
By employing these metrics, developers can benchmark the overall effectiveness of LLMs in performing tasks that require a deep understanding of language and the ability to generate human-like text. This evaluation process for machine learning tools is essential for refining and enhancing the model's capabilities to ensure it meets high standards of performance and reliability.
LLM System Evaluation:
In contrast, LLM system evaluations, also known as task evaluations, are more specific and often carried out by end-users or engineers who integrate these models into specific applications. These evaluations are tailored to the particular components the engineer can control, such as the prompt and context within which the model operates. This form of evaluation is crucial for fine-tuning the model to specific use cases, ensuring that the model not only performs well generally but excels in particular scenarios relevant to the user's needs.
Differences and Implementation:
While model evaluations are broad and conducted early in the model's development life cycle, system evaluations are ongoing and more focused, often integrated into the lifecycle of specific applications. Model evaluations are used to compare models at a high level and are typically executed by the model's developers as they refine and enhance the model's capabilities. System evaluations, however, are performed by users who apply the models in specific contexts, focusing on optimization and contextual performance, which are critical for operational success.
The insights from these evaluations inform adjustments and improvements, guiding both developers and practitioners in enhancing model performance tailored to both broad and specific requirements.
Source: Author
Key Metrics for LLM Model Evaluation
Evaluation methods for LLMs involves assessing their performance across various tasks such as retrieval, question-answering, summarization, and entity extraction. Each task requires specific metrics to accurately measure the effectiveness and efficiency of LLMs. Below is a comprehensive table summarizing these metrics for the top tasks associated with LLMs:
These metrics are crucial for ensuring that LLMs perform optimally across varied tasks, providing a framework for developers to fine-tune models to meet specific needs and operational requirements effectively. Each metric serves a unique role, from validating the precision of extracted information to the relevance and quality of the generated text, enabling comprehensive evaluation of LLM capabilities.
Leading Frameworks for LLM Model Evaluation
Evaluating LLMs requires robust frameworks that can provide accurate and reliable metrics across different use cases, such as document retrieval, question-answering, and DeepFake detection. Below is an analysis of the top evaluation frameworks currently available, highlighting their pros, cons, and recommended use cases.
1. DeepEval
- Use Cases: Best suited for a wide range of LLM evaluations including retrieval, summarization, and bias detection.
- Pros: Offers a comprehensive set of over 14 metrics, easy integration with pytest for developers familiar with unit testing, and the ability to generate synthetic datasets.
- Cons: While it provides detailed feedback on metric scores, the complexity of setup can be a barrier for less technical users.
- Recommended For: Developers seeking detailed analytics on performance and those integrating evaluation into automated testing pipelines.
2. MLFlow LLM Evaluate
- Use Cases: Ideal for question-answering and retrieval augmented generation tasks.
- Pros: Known for its simplistic, modular approach that allows easy customization and integration into existing workflows.
- Cons: Limited to the types of evaluations it supports, primarily focusing on QA and RAG.
- Recommended For: Teams that require a flexible and intuitive tool for integrating evaluation within ML pipelines.
3. RAGAs
- Use Cases: Specifically designed for Retrieval Augmented Generation systems.
- Pros: Focuses on core metrics like faithfulness and contextual relevancy which are crucial for RAG evaluations.
- Cons: Limited feature set outside natural language processing (NLP) like RAG applications and non-self-explaining metrics which can complicate troubleshooting.
- Recommended For: Applications where retrieval is a critical component and precise measurement of retrieval quality is required.
4. Deepchecks
- Use Cases: Best for evaluating the LLM itself rather than full systems or applications.
- Pros: Offers excellent visualization tools and dashboards that help in understanding model performance visually.
- Cons: Setup and configuration can be complex and may deter less experienced users.
- Recommended For: Organizations that need deep insights into model behavior and prefer visual over numeric data representation.
5. Arize AI Phoenix
- Use Cases: Suitable for monitoring and evaluating deployed LLM applications, focusing on metrics like toxicity, QA correctness, and hallucination.
- Pros: Provides extensive observability into LLM applications, ideal for deployed systems.
- Cons: Offers a more limited range of evaluation criteria which may not cover all potential needs.
- Recommended For: Teams needing real-time monitoring and evaluation of LLMs in production environments.
This comparative analysis helps in selecting the appropriate framework based on specific needs and the nature of the task at hand. Each framework has its unique strengths and can be chosen based on the complexity of the LLM task, the depth of metrics required, and the operational environment (development vs. production).
Source: Author
Optimizing LLM Model Performance Post-Evaluation
Optimizing the performance of o LLM after evaluation involves several strategic techniques to refine the model’s efficacy. Here’s how you can boost the performance of your LLM based on the outcome of your evaluations:
1. Prompt Engineering
When to Use: Prompt engineering should be your first approach right after evaluating your LLM. It’s especially useful when the model outputs need refinement in accuracy or style to better meet the use case.
Overview: Prompt engineering involves crafting and refining the inputs given to the LLM to guide it towards generating the desired outputs. This might include specifying the structure of the response, providing context, or using examples to direct the model's attention. It's a crucial step because it can drastically change the quality and relevance of the output by merely altering the input prompts.
Source : Author
2. Retrieval-Augmented Generation (RAG)
When to Use: Implement RAG if your model lacks access to external information or needs to integrate more context for generating responses. It’s vital for tasks requiring up-to-date knowledge or specific details not contained within the training data.
Overview: RAG combines the capabilities of neural networks with external data retrieval. By fetching relevant documents or data at runtime, RAG allows the model to produce responses that are informed by the latest or most relevant information. This technique is beneficial for enhancing the model’s responses with accuracy and depth, particularly in dynamic fields like news, finance, or medical research.
Source: Author
3. Fine-Tuning
When to Use: Fine-tuning is appropriate after initial evaluations indicate that the general capabilities of the model need adjustment to better suit specific tasks. This is often used to improve performance on niche tasks or to adapt to unique datasets.
Overview: Fine-tuning adjusts the underlying parameters of an LLM based on a targeted dataset, which helps the model to perform better on tasks similar to those in the dataset. It involves continued training of the model on task-specific data, allowing the model to learn nuances and intricacies it might not have captured during initial training. This is particularly effective for specialized applications, ensuring that the model behaves in a way that aligns closely with the specific needs of the application.
General Strategy:
- Evaluation First: Always start with a robust evaluation to identify the strengths and weaknesses of your model. Metrics from evaluations will guide which optimization technique will be most effective. This process involves using both quantitative metrics and qualitative assessments to ensure a comprehensive understanding of the model's performance. Additionally, it is common practice to manually inspect the results to verify alignment with requirements. While manual inspection is valuable, integrating evaluation metrics can make the process more reliable and accurate(Murahari et al., 2023).
- Iterative Process: Optimization is rarely a one-off process. It often requires multiple cycles of evaluation and adjustment to hone the model’s performance. This iterative approach helps in continuously improving the model by refining it based on successive rounds of feedback and performance data.
- Combining Techniques: In many cases, a combination of these techniques will yield the best results. For example, you might start with prompt engineering to refine input handling, then use Retrieval-Augmented Generation (RAG) to broaden the model's access to information, and finally apply fine-tuning to deeply adapt the model to specific tasks. Manual inspection of results, complemented by evaluation metrics, ensures that the model not only meets but exceeds the desired performance standards(Tsuda et al., 2016).
By systematically applying these strategies, developers can significantly enhance the performance of LLMs, ensuring they not only meet but exceed the requirements of their specific applications. This iterative cycle of evaluation and optimization helps in maintaining the relevance and effectiveness of the model over time.
Conclusion
Source: Dall-E
In conclusion, the ability to effectively evaluate and optimize Large Language Models (LLMs) is essential for harnessing their full potential across diverse applications. Through strategic use of prompt engineering, Retrieval-Augmented Generation (RAG), and fine-tuning, developers can tailor models to meet specific needs and ensure high performance. Each technique offers unique benefits, from refining input handling and integrating external data to customizing the model’s behavior for particular tasks. By continuously applying these methods in a thoughtful, iterative process, and leveraging robust evaluation frameworks, developers can create LLMs that are not only functional but excel in their designated roles. This ongoing cycle of evaluation and optimization is crucial for developing LLM applications that are efficient, effective, and aligned with the evolving demands of the tech landscape.


