Binary vs. Product Quantization: Optimizing Multimedia Database Storage and Retrieval

Introduction
In today's digital landscape, the volume of multimedia content is skyrocketing, posing significant challenges for efficient data management and retrieval. From social media platforms to e-commerce websites, businesses rely on multimedia databases to store and serve images, videos, and other rich media. However, managing these massive data sets can be costly and time-consuming, particularly when it comes to storage requirements and retrieval speed.
Enter vector databases, a powerful solution for organizing and querying high-dimensional data, such as multimedia embeddings. While vector databases offer a robust framework, companies still grapple with the issue of maintaining these databases efficiently, both in terms of cost and retrieval speed.
In this blog post, we'll explore the fascinating world of quantization, a technique that promises to revolutionize the way we handle multimedia databases. We'll dive into the nitty-gritty of quantization, unveiling its magic and the potential it holds for storage reduction and speed enhancement. Additionally, we'll compare two popular quantization methods, Binary Quantization, and Product Quantization, to help you choose the right approach for your specific needs.
What is Quantization, and Why Does it Matter?
Quantization is a process that converts high-dimensional, floating-point data (such as embeddings) into compact, discrete representations. By mapping these embeddings to lower-dimensional subspaces and encoding them using fewer bits, quantization can dramatically reduce the memory and storage requirements for multimedia data, such as images and videos.
Imagine compressing a 32-bit floating-point value into a mere 1-bit representation. This seemingly impossible feat is achievable through quantization, resulting in a whopping 32x reduction in storage requirements. In the world of multimedia databases, where petabytes of data are the norm, the potential savings are staggering.
The Magic Behind Quantization:
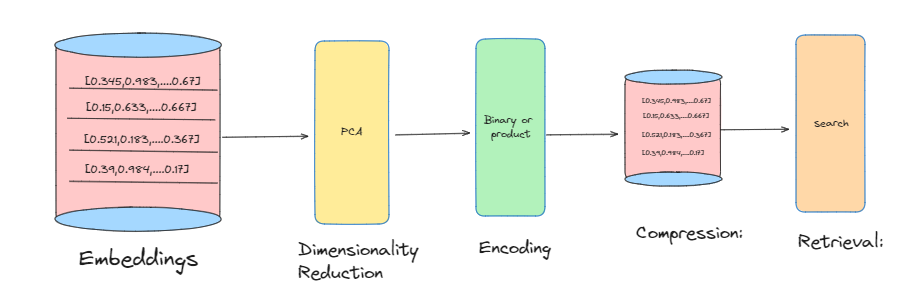
Image By Author
The process of quantization is a fascinating dance between dimensionality reduction and clever encoding. Let's break it down step-by-step:
1. Embeddings: Multimedia data, such as images or videos, are converted into high-dimensional embeddings, capturing their essential features.
2.Dimensionality Reduction: These embeddings are then compressed into a lower-dimensional subspace through feature engineering techniques, such as Principal Component Analysis (PCA) or autoencoders.
3.Encoding: The low-dimensional sub-vectors are mapped to discrete values using encoding schemes like binary or product quantization.
4. Compression: The encoded values are stored in a compact format, significantly reducing the memory footprint.
5. Retrieval: When a query is made, the compressed data is efficiently retrieved, and the original embedding is reconstructed, allowing for accurate similarity searches.
Is Quantization Worth the Hype?
Absolutely! Quantization offers numerous benefits, particularly for media companies dealing with vast amounts of multimedia data. Storing and processing these enormous datasets can be prohibitively expensive, making quantization a game-changer.
By reducing storage requirements, quantization not only cuts costs but also enhances data retrieval efficiency. Compressed data can be accessed and processed faster, improving response times and overall user experience. Moreover, quantization enables efficient similarity searches, a crucial aspect of multimedia applications, such as image recognition and recommendation systems.
BinaryQuantization vs. Product Quantization:
While quantization is a powerful technique, there are different approaches to consider, each with its own strengths and trade-offs. Two popular methods are Binary Quantization (BQ) and Product Quantization (PQ).
Image By Author
Binary Quantization (BQ) is a simple yet effective approach that maps each element of the input vector to either 0 or 1, resulting in a compact binary representation. The formula for BQ is:
B(x) = sign(x)
Where `x` is the input vector, and `sign` is the sign function that returns -1 for negative values and 1 for positive values.
Image By Author
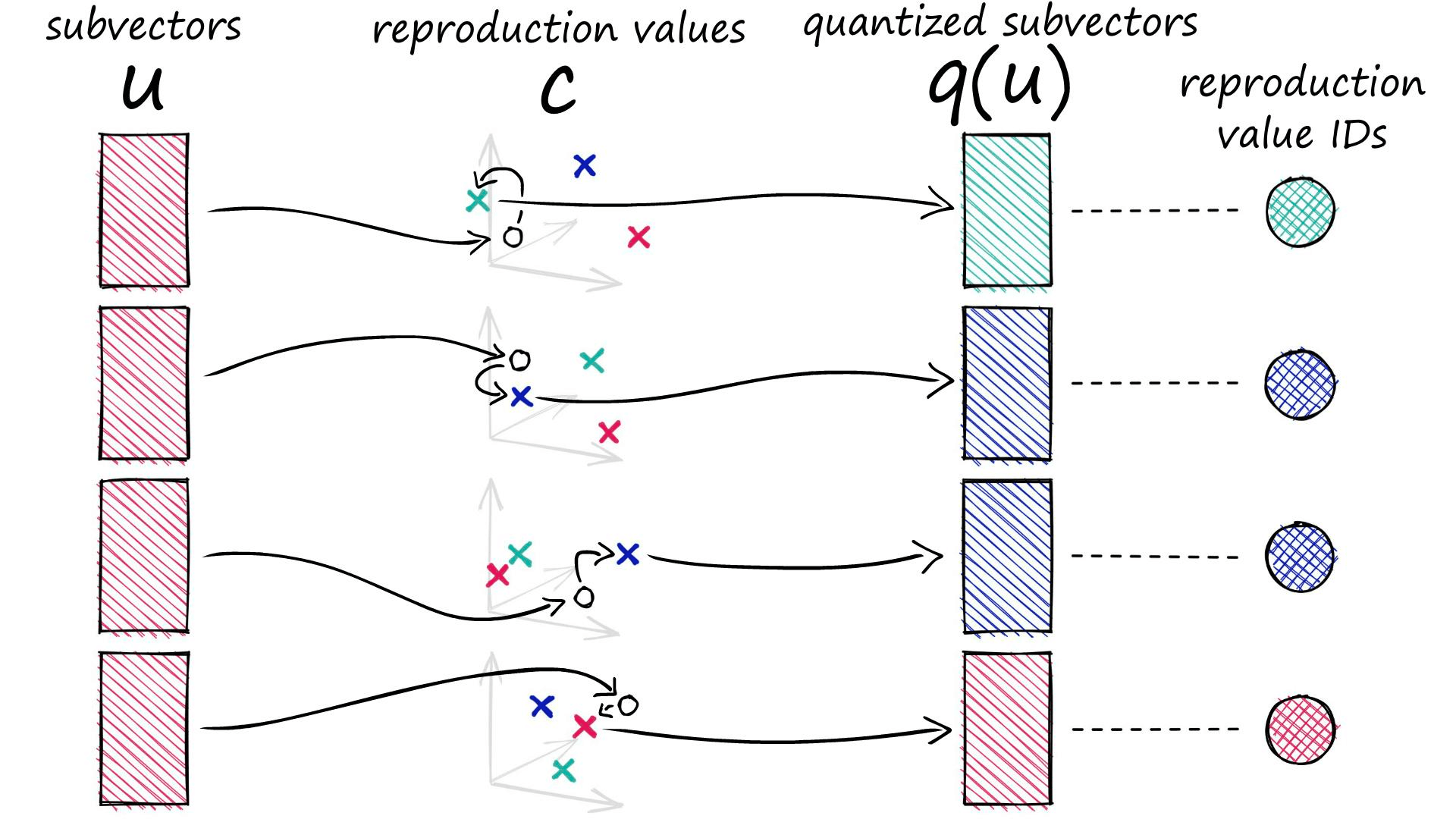
Product Quantization (PQ), on the other hand, is a more sophisticated technique that divides the input vector into multiple sub-vectors, quantizing each sub-vector separately. The formula for PQ is:
PQ(x) = [q_1(x_1), q_2(x_2), ..., q_m(x_m)]
Where `x` is the input vector, `x_i` are the sub-vectors, and `q_i` are the quantization functions for each sub-vector.
Choosing the Right Quantization Approach:
When selecting a quantization method for your multimedia database, it's crucial to consider your specific requirements and trade-offs:
Memory: If minimizing memory footprint is the primary concern, Product Quantization is the way to go. Its compact product representation offers substantial storage savings.
Speed: For applications demanding lightning-fast retrieval, Binary Quantization is the clear winner. Its simple encoding and decoding process ensures optimal speed.
Performance: If you prioritize search accuracy and precision, Product Quantization may be the better choice. By independently quantizing sub-vectors, it can better capture the nuances of high-dimensional data, leading to improved retrieval performance.
However, it's important to note that Product Quantization is more computationally complex, requiring additional resources for training and encoding.
Comparative Analysis with Code Examples:
To illustrate the power of quantization for multimedia databases, let's dive into a practical example using a popular image dataset: Flickr-8k . We'll implement both Binary Quantization and Product Quantization on the first 500 images, comparing their performance in terms of memory usage, retrieval speed, and accuracy.
unknown nodeunknown nodeunknown nodeunknown nodeunknown nodeIn this example, we first import the necessary libraries and preprocess the Flickr-8k dataset. We then implement Binary Quantization and Product Quantization, encoding the dataset using both methods.
The results section compares the memory usage of the original data, Binary Quantized data, and Product Quantized data. We also evaluate the retrieval speed by computing distances between subsets of the data using both quantization methods.
While this is a simplified example, it demonstrates the core concepts and provides a starting point for exploring quantization techniques tailored to your specific multimedia database needs.
Conclusion
In the ever-growing realm of multimedia data, quantization emerges as a powerful ally, enabling efficient storage and retrieval while preserving the essence of high-dimensional embeddings. By understanding the trade-offs between Binary Quantization and Product Quantization, companies can make informed decisions that align with their priorities, whether it's optimizing for memory, speed, or performance.
As we continue to navigate the data-driven landscape, embracing quantization techniques is crucial for businesses to stay competitive and provide seamless multimedia experiences. Looking ahead, the integration of quantization with emerging technologies like edge computing and 5G networks opens up exciting possibilities for real-time multimedia processing and retrieval. Ongoing research in advanced quantization techniques holds the potential for even greater optimization. By adopting quantization strategically, companies can future-proof their operations and deliver exceptional user experiences in an increasingly multimedia-driven world.



{kind=link}